Detecting Stale Data for IIoT data
Exposing the Hidden Risks in Industrial Time-Series Data



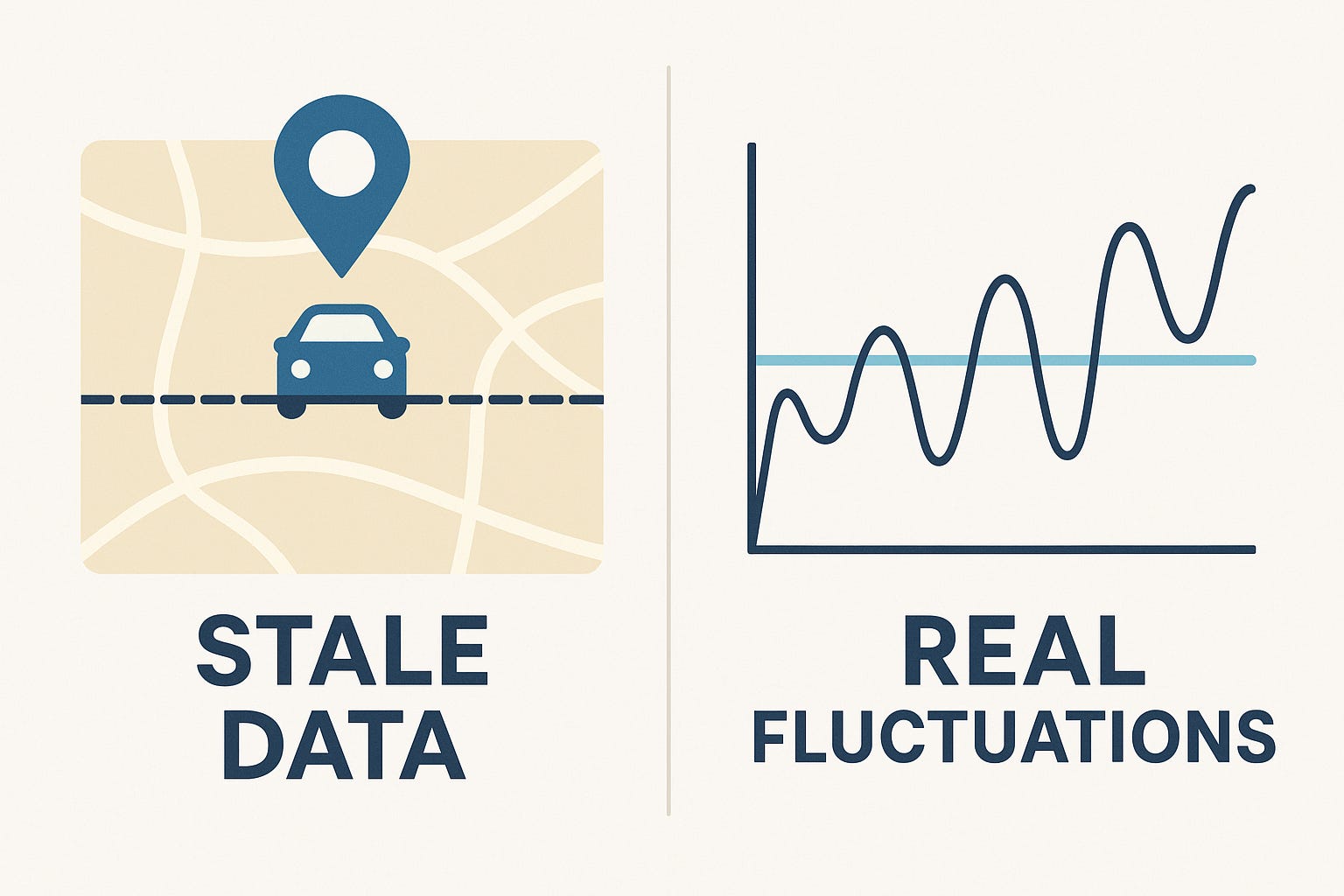
What is stale data?
Stale data is data that looks alive but isn’t. A sensor keeps reporting the same value while reality has already changed. Think of it like driving with yesterday’s GPS coordinates: your dashboard shows a valid position, but it no longer reflects where you actually are.
In an industrial context, stale data means the physical process has moved on, while your systems: dashboards, models, or control logic still operate on outdated information.
Why does stale data matter?
Stale data isn’t just an IT nuisance. It directly impacts:
Safety – A flatlined pressure transmitter can hide dangerous conditions until it’s too late.
Compliance – An emissions analyzer that silently stops updating can mislead regulators.
Profitability – Faulty signals drive wrong control actions, skew billing, or trigger costly downtime.
Productivity – Teams lose hours cleaning and validating data instead of delivering value.
👉 Stale data doesn’t just slow you down, it creates hidden risks across the entire operation.
Why is it so hard to detect?
At first glance, stale detection sounds simple: check if values repeat.
But in practice, it’s far more complex:
Stable processes – some operations naturally hold steady values for hours.
Process regimes – pumps or batch processes switch states, creating “false flatlines.”
Different failure modes – fouling, miscalibration, and communication dropouts all manifest differently.
Scale – tens of thousands of tags per site make manual checks impossible.
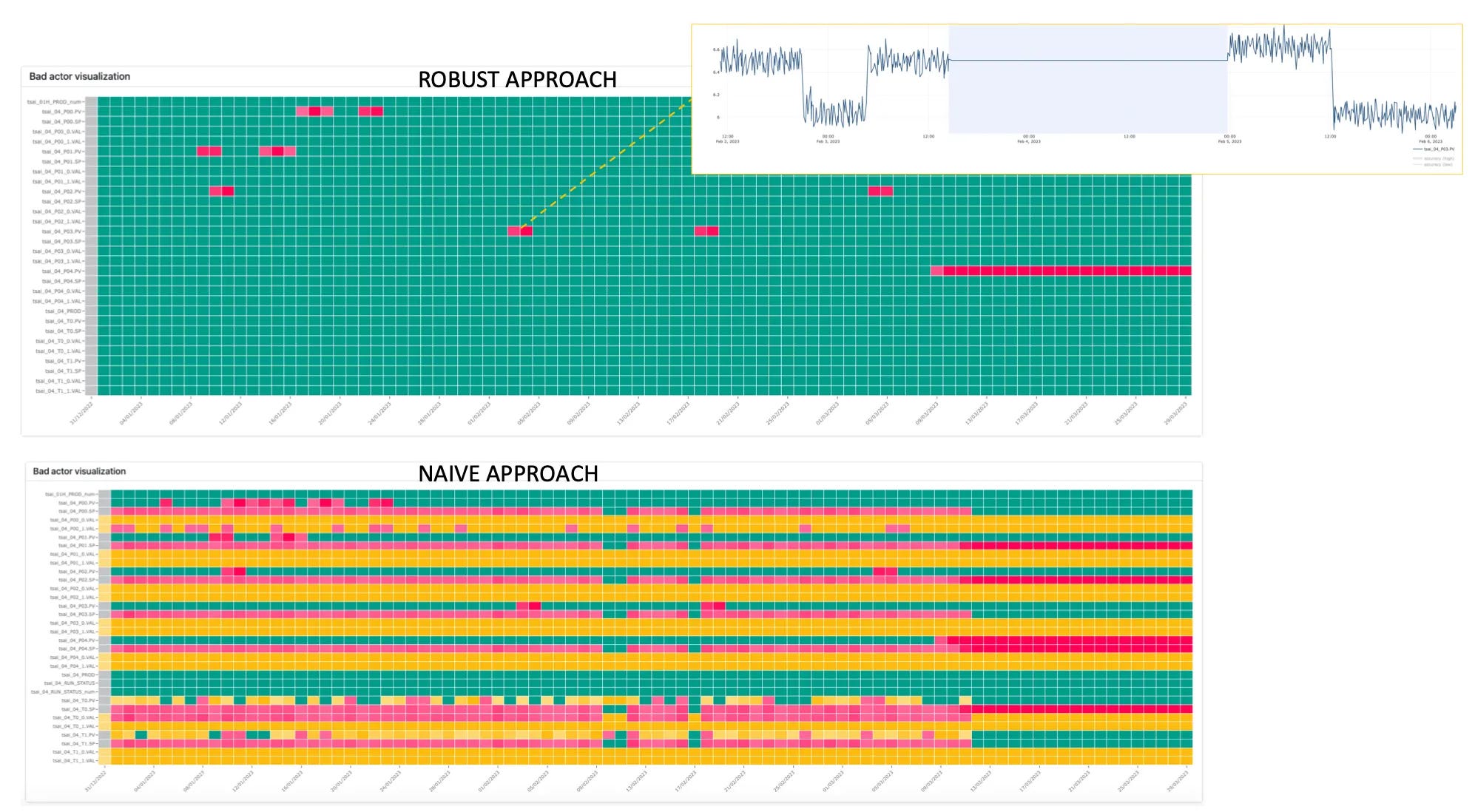
Naïve vs. Robust Detection
The naïve approach to stale data is to set a simple rule: “If a sensor reports the same value for more than X minutes, raise an alert.” It works as a prototype, but it collapses in the real world. Stable processes, regime switches, or compression artifacts all trigger floods of false positives. Operators quickly learn to ignore the alarms — defeating the purpose.
A robust approach goes further: it understands the context of the signal. It adapts thresholds to sensor type, asset behavior, and operating regimes. It learns what “normal” looks like, so it can separate true staleness from a legitimately steady process. By combining statistical analysis, physics-aware checks, and fleet-wide learning, robust detection cuts noise while scaling across thousands of sensors.
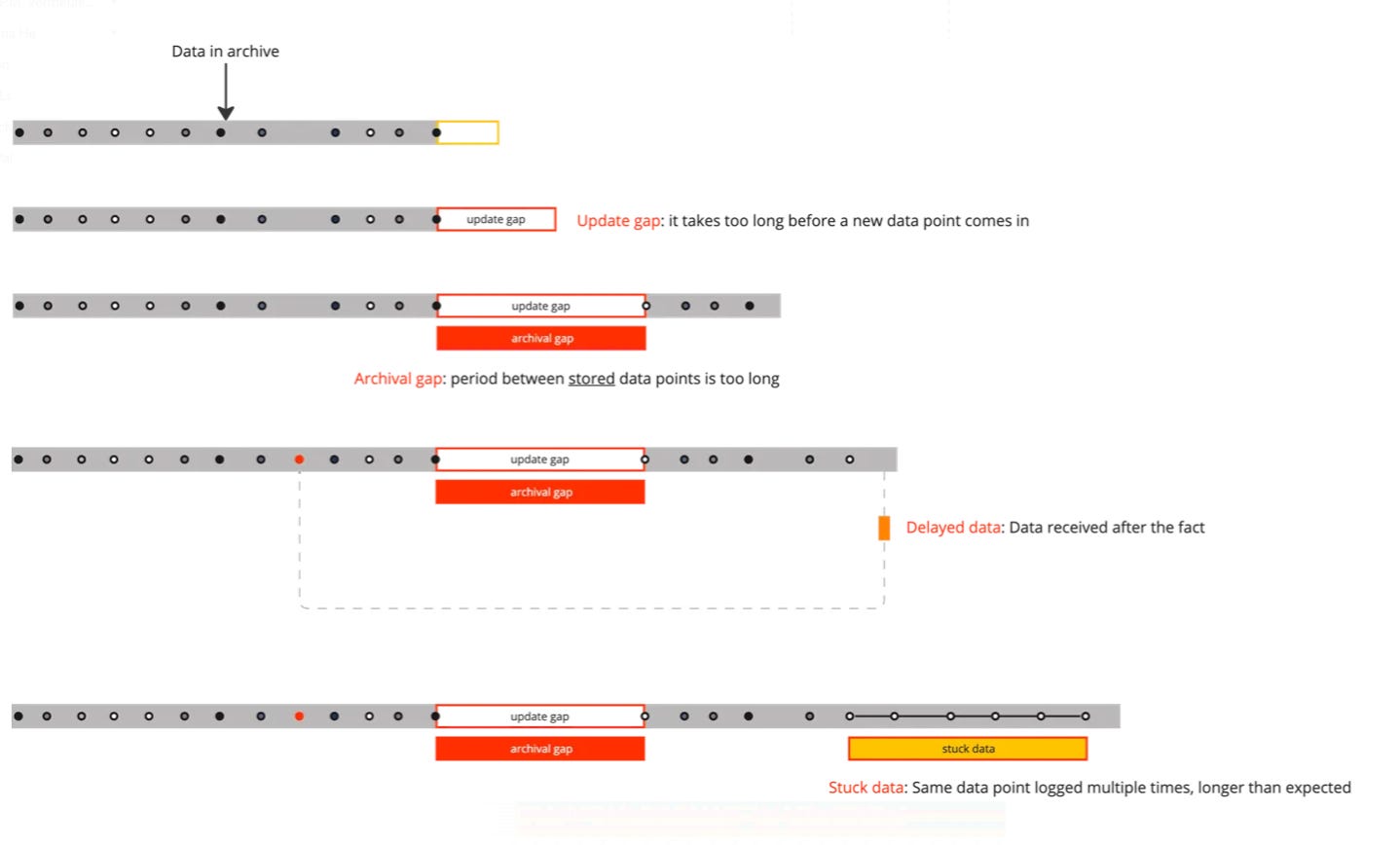
The 4 failure modes of stale data
Staleness isn’t one thing. It shows up in different guises:
Update gap – no new data arrives in time.
Archival gap – updates arrive late, leaving holes in history.
Delayed data – values arrive retroactively, confusing downstream logic.
Stuck values – the same value keeps repeating, even when reality changes.
IT vs. OT stale data
In IT systems, stale data usually means a batch job didn’t run or an ETL pipeline froze.
In OT/IoT, the challenges are different:
Non-equidistant time series with compression applied
Sensors that get “almost stuck” (values barely changing, but not flat)
Bursty data patterns from discrete operations (e.g., a welding robot)
Failures at many layers: device, gateway, network, historian, ETL job
The result: staleness is more complicated to spot and far more costly.

The hidden cost: Data Downtime
Stale data creates Data Downtime, periods when data is present but untrustworthy.
Analytics teams waste 50–70% of their time cleaning up datasets.
AI models trained on silent sensors become copilots of lies.
Operations lose trust in dashboards, digital twins, and predictive models.
The cost curve is brutal:
Fixing at the source = $1
Fixing after analytics or compliance = $10–$20
Fixing after it hits operations or invoices = $100+
Yet unlike IT downtime, data downtime isn’t even a boardroom KPI. That needs to change. Right?
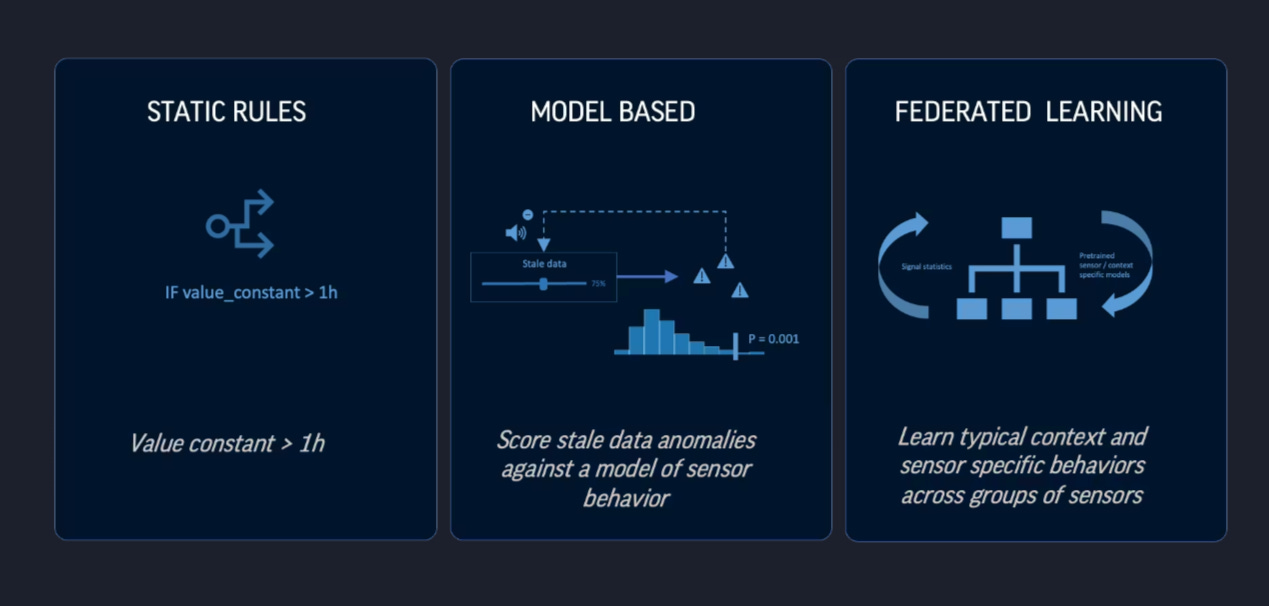
Detection approaches
There are three main ways to detect staleness:
Rule-based – Simple thresholds (e.g., “flag if constant for >1 hour”). Easy to start, but brittle at scale.
Model-based – Learn thresholds dynamically from sensor behavior. Reduces false positives and scales better.
Federated learning – Use group behavior across fleets of similar sensors to improve accuracy further.
👉 Rule-based is the fast start.
👉 Model-based is the scalable path.
👉 Federated learning is the future.
DIY vs. platform
Many data teams start by coding their own stale data checks in Databricks or Python notebooks. That’s fine for pilots — but the total cost of ownership escalates:
Dozens of thresholds to tune per signal
Heterogeneous fleets requiring sensor-specific rules
Visualization and alerting for business users
Integration into downstream dashboards and pipelines
What starts as a few lines of Python quickly turns into a system you need to maintain. That’s why more teams adopt dedicated observability platforms that “speak” IoT/OT natively.
How to fight back
The good news: stale data can be managed.
Continuous monitoring across all tags, not just critical ones.
Physics- and asset-aware validation (e.g., if the valve opens, flow should increase).
Reliability scoring so data trust can be measured like uptime or asset health.
Proactive triage & repair: alerts that reduce noise, with AI-driven suggestions for remediation or even temporary data repair.
Takeaway
Stale data is a silent threat. It looks harmless, but it undermines safety, trust, and profitability. If crude oil powered the last century, refined and reliable sensor data will power the next. And if uptime is non-negotiable for equipment, then data uptime must become non-negotiable for operations.
👉 Next in the 101 Tech Talks series: we’ll dive into sensor drift — how minor deviations become big problems.
 | A guest post by
|
 | A guest post by
|
The original article by Thomas: https://medium.com/p/bf9ed0609ef7